译者:孙薇
小象科技原创作品,欢迎大家疯狂转发;
机构、自媒体平台转载务必至后台留言,申请版权。
MySQL5.7
MySQL5.7的有趣变化

MySQL的GA版本仍是5.6版,不过MySQL5.7开发版本的发布确实为数据库管理系统的世界引入了一些令人兴奋的变化。它是否值得尝试呢?本文将会对它的几个崭新功能进行更进一步的探究,你可以借以决定是否要尝试。
1
原生支持JSON
JSON(Java Script Object Notation的缩写)是一种存储信息的格式,可以很好地替代XML。如果还没用过JSON,可以看下这个非常简单的例子:

直至MySQL5.7.8才对JSON提供支持,不过毫无疑问这个功能是MySQL用户极为热衷的。在之前的版本中,只能以strings之类的通用形式来存储JSON文件,这种做法当然有其缺陷:必须自行确认/解析数据、解决更新中的困难、或在执行插入操作时忍受较慢的速度。
从MySQL5.7.8之后,由于原生支持JSON,处理JSON文件就非常简单。现在执行插入与更新操作时可以自动确认了,而且效率很高;使用新定制的一系列功能访问对象与数组成员的速度也更快了。尝试用JSON列来创建一个简单的user表格:
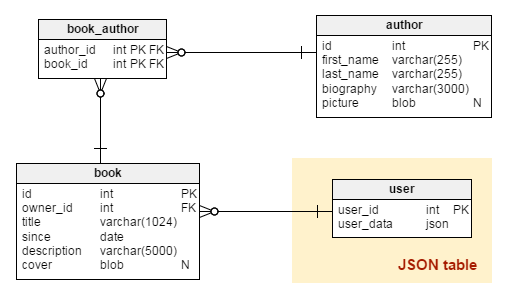
下一步,用新的列类型来创建几条命令行,得到的表格可能会像下面这样:
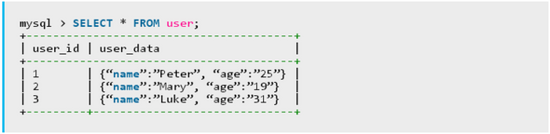
现在我们可以运用新的JSON功能来轻松处理JSON列了。举个例子,如果想要列出用户名,可以使用下列query命令:

可以用< !=这些符号来比较JSON值,还能将它们转为其他类型。这些还不够吗?简单来说,MySQL现在已经全面支持JSON文档了。
2
在ONLY_FULL_GROUP_BY中
具有更高的自由度
如果你学过SQL教程或教材,也许还记得GROUP BY中的这条黄金定律:SELECT列表中的任何非聚合字段都必须包括在GROUP BY表达式中。这条定律遵守SQL92标准,而且是很安全的假设——非聚合列可以有多个值,因此如果不进行分组,数据库引擎在判断取哪个值的时候就会有困难。
在SQL99标准中这条定律有修改,变成了在SELECT列表中的任何非聚合列都必须在功能上依赖GROUP BY列表。 这代表着如果在一个列有固定值,这个值与该列所属的GROUP BY表达式相同,则只要它的依赖性是通过主键或唯一键显示,就无需再进行分组排列。
举个简单的例子:如果有一张book表,其book_id列是主键:
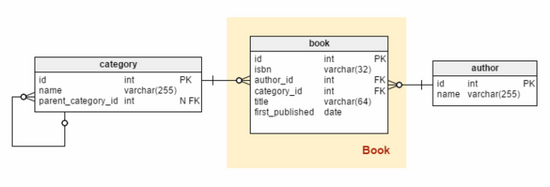
我们可以写出下列查询语句(不过没太大用):

这个查询命令并不符合SQL92标准,该列的标题未列在GROUP BY表达式中,它也不是聚合列。但由于其book_id是主键,同时每个book只能有一个标题,因此这个标题在功能上依赖于该book_id。因此,在SQL99中这条查询命令完全清晰易读。
之前,MySQL中的ONLY_FULL_GROUP_BY模式遵守SQL92标准的规定,在默认情况下是关闭的。MySQL并未强求严格按照SQL92标准编写查询命令。在MySQL5.7.5中,ONLY_FULL_GROUP_BY的含义改变了,由于遵守SQL99,现在将实现更为复杂的功能。也就是说,有时候要写的代码少了,却仍旧能实现查询功能。现在的 ONLY_FULL_GROUP_BY默认更加宽泛。在这里能找到关于该问题更详细的解释。
3
在InnoDB中
支持空间数据类型
空间数据类型常用于处理地理空间信息,它们描述了几何对象的真实坐标与形状。在MySQL中,可以使用像Point、LineString或Polygon之类的几何对象代表,还有一些很有用的空间函数。例如,我们可以创建一个简单的表格来保存邮编,其中会包含一个描述特定邮编区域的area列:
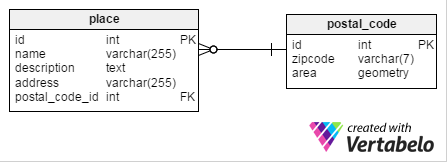
每个区域可以用一个Polygon来代表:

现在我们可以通过st_contains函数找到地图上指定Point的邮编,来自动确定指定Point是否包含在该Polygon内:

在MySQL5.7之前的版本中也能使用空间数据类型,不过是以BLOBs(Binary Large OBjects)类型存储在InnoDB中,这种类型可以保存不等量的数据。在新的MySQL中,空间数据类型被映射到一个单独的内部数据类型DATA_GEOMETRY上。现在这些数据类型可以与其他存储为BLOB类型的信息分开处理了。从MySQL5.7.5以后,空间数据类型甚至可以使用空间索引了:

4
更好地支持
对亚洲语言的处理
一般出现在MySQL中的全文解析器将全文分解为词汇,使用空格作为导向。这种做法在拉丁语系的语言中(如英语)是个有用的解决方案,但是对于亚洲的表意文字——中文、日语、韩语(通常缩写为CJK)则没什么用。这些语言不使用任何文字分隔符,因此词汇的开始和结束就不甚明了。
现在MySQL使用n-gram分析程序将n个字符的连续序列分割成为n个字符长度的token。假设n=3,词汇“ABCDE”就能产生“ABC”,“BCD”和“CDE”。在处理表意文字时这种做法十分有效。例如,中文表述“工作人员”由以下两个词组成:“工作”和“人员”。我们知道在这个表述中的词组至多有2个字符长,因此可以使用n-gram分析程序,设定n=2,将这个表述解析成:工作、作人和人员。第二个token由中间的两个字符(作人)组成,实际上是另一个中文词,因此我们可能需要进一步分析这些token,以确认哪些才是正确的词组。
还有另一个更为复杂的插件名叫MeCab,专为日语设计,从形态上分析日语句子并自动断出词。比如这句话:
ワルシャワはポーランドの首都です (华沙是波兰的首都)
可以转成:
ワルシャワ(华沙)
は(标出话题)
ポーランド(波兰)
の(的)
首都(首都)
です(礼貌的连系动词)
如果处理的是中文,也可以从较小的全球化进程中获益——MySQL5.7.4设有gb18030字符功能,对应着中国国家标准GB18030。多亏了这些转变,处理亚洲语言容易多了。
5
还有很多其他的功能!
MySQL5.7中当然还有其他的新增功能与功能改善。如果想要了解更多内容,就戳【 阅读原文 】吧,其中简单列出了所有改动。